Deepseek GRPO 中的 KL Divergence
起¶
在 Deepseek R1 发布之后,看到了论文中 RL 的算法用的是 GRPO,而 GRPO 是在之前 Deepseek Math 的论文中被提出来的。GRPO 的目标函数如下:
这里我们只看最后的 KL Divergence(KL 散度) 部分。关于最后 KL 散度的实现,论文特别做了说明:
And different from the KL penalty term used in PPO, we estimate the KL divergence with the following unbiased estimator (Schulman, 2020), which is guaranteed to be positive.
也就是说其使用的 KL Divergence 与 PPO 不同,GRPO 中采用了 Schulman 在博客 中提到的一个无偏估计。论文中使用的是博客中提到的
首先 KL 散度的公式如下
定义
那么有
因此,论文中的
此时,
对应地,
到这里为止,论文中 KL 散度的推导的就完成了,一切都很清晰。后来我又读了几篇关于 KL 散度不对称性的博客,比如这篇Reverse vs Forward KL, 里面提到 Reverse KL Divergence 是类似
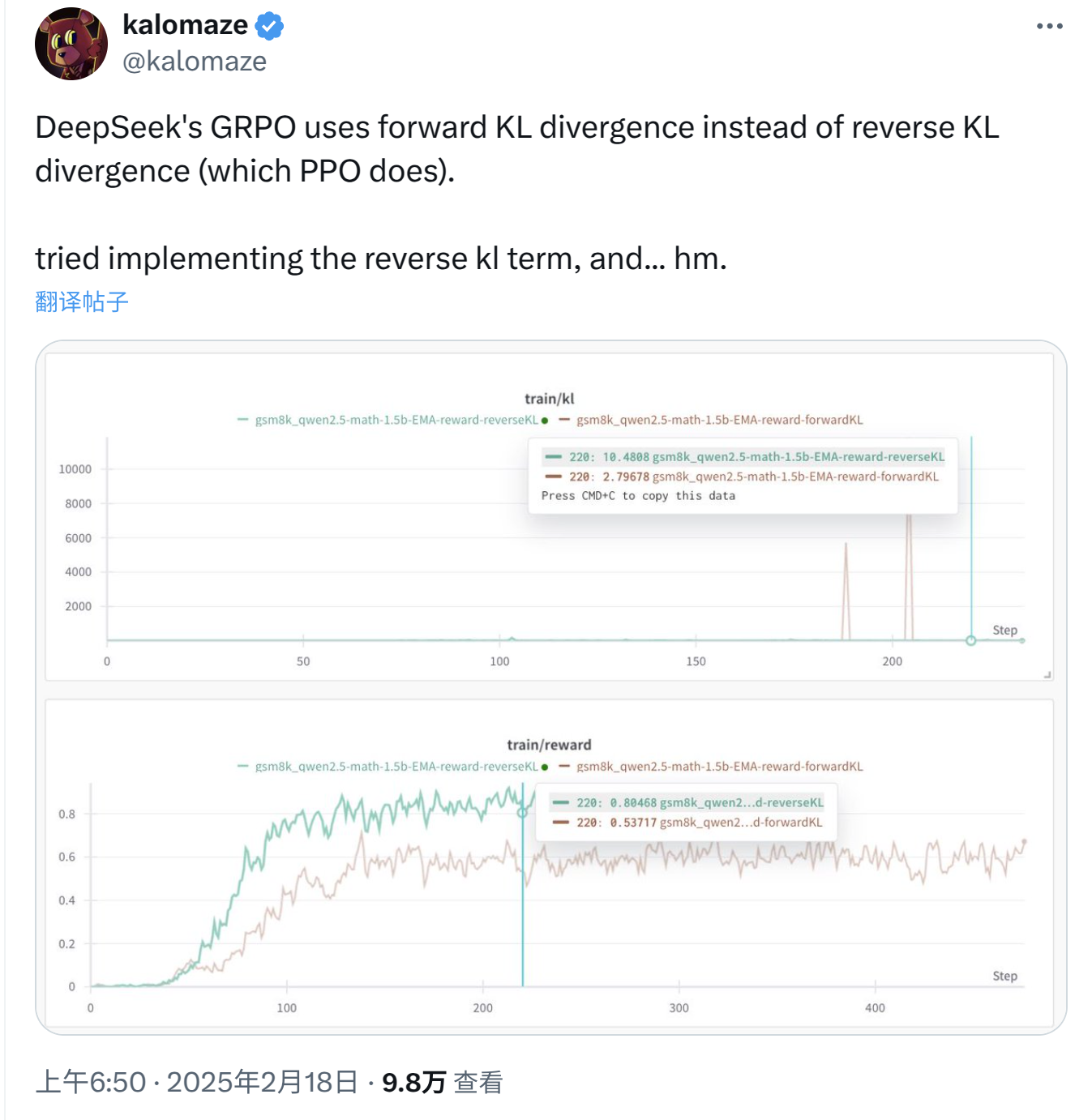
承¶
看到帖子的时候我就在想,这不可能啊,这么明显的错误评论区肯定有一堆人指正的。但事实是没有人反对,而且有两个哥们让人印象深刻:其中一个说,啊对对对,我们之前一篇论文也证明了 Forward 比 Reverse 更好;另外一个哥们是吟唱流,连发七八条帖子去分析。
到这里,我认识到可能是我错了,所以去请教 LLM 老师们,发现老师也都说 GRPO 就是用的 Forward KL。我郑重抗议说他们不对,应该是 Reverse KL,老师们并不接受...所以我开始反思我哪里想错了,并开始向认识的朋友们请教。(再次感谢各位!)不过辗转几次下来,好像也没什么定论。期间我又推导了几次,还是没找出哪里有问题。这个问题一直在我脑子里,就像一小朵乌云一样飘在那里,让我很是不好受......
转¶
紧接着 Grok3 发布了,我赶紧试了下这个问题。Grok3 告诉我说,GRPO 用的是 Reverse KL Divergence,分析的思路也都很正确。我开始意识到我可能并没错,错的是......
转折点是看到 Unsloth 发布的博客 Long-context GRPO,里面明确写道 GRPO 就是用的 Reverse KL Divergence:
The reference GRPO implementation uses the reverse KL divergence, not the forward KL divergence.
至此,我心中的那片乌云终于消失了...
既然谈到了 Reverse KL 和 Forward KL,不妨让我们更直观地理解一下两者的区别。下图来自博客Reverse vs Forward KL。
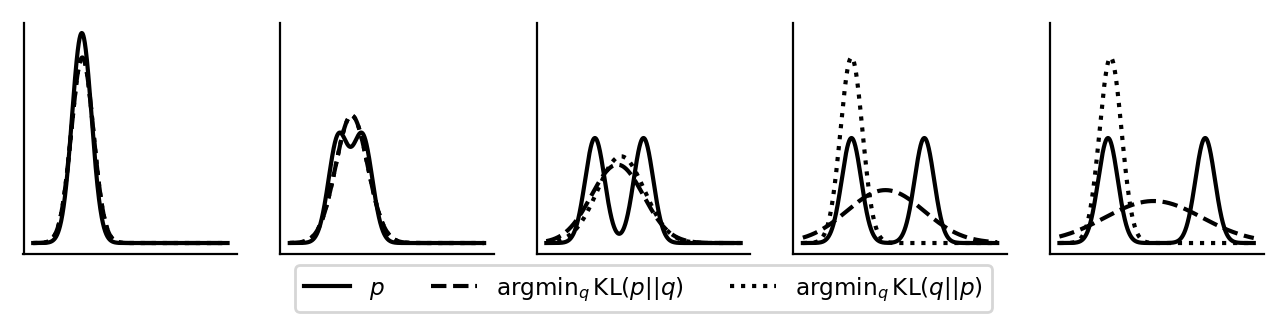
其中实线代表
对于两者的区别,结论是:Reverse KL 的行为是 Zero-Forcing/Mode-Seeking;Forward KL 是 Mass-Covering/Mean-Seeking。
Reverse KL 的公式如下
因为在
反观 Forward KL:
因为是
回到在 LLM 训练中,用 Reverse KL 和 Forward KL 有什么差别吗?Unsloth 其实给出了实验的分析,其实看结果似乎并没有太大的区别:
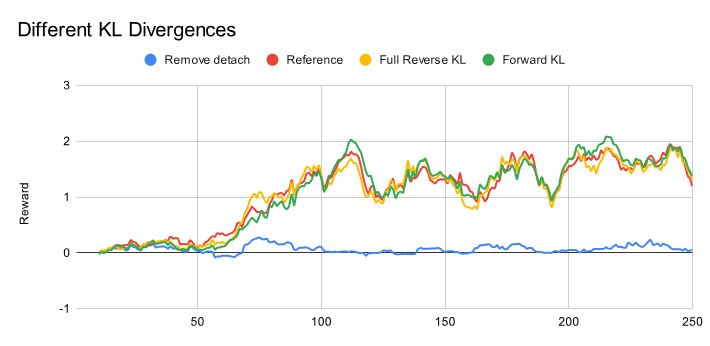
下面要说的是目前的一些猜想 (aka 暴论:),笔者并没有去实际验证,仅作为拓展思考:这里 Reverse KL 和 Forward KL 没有差别的原因可能类似上面博客模拟实验中
合¶
回看这段颇有意思的经历,我逐渐明白社交网络的人多是为了自己,事实怎样对于他们来说是次要的。在 LLM 时代,受硬件的限制多少还有的,“Money is all your need”并非没有道理……很多想法没有显卡根本无从验证,在这个时候是选择相信自己的判断还是选择相信“主流的观点”是一个值得思考的问题。